
Backstory
🔨 分享一个有关立项的故事。
去年月底某友在群里分享了一个他自己 fork 的 epicgames-claimer 的项目,添加了 Actions 的特性,能够借助工作流实现定时领周免的需求(非滥用),高能现场如下:
当时我正在搓其他项目的代码,甚至还没点开这个链接,只是感觉这个点子感觉挺“曼妙”的,仅仅是留下印象而已。但巧就巧在- -我当时正在搓的项目是与 anti-CAPTCHA 密切相关的任务。
直到今年年初,1月14日左右,项目告一段落,有了阶段性的积累,对整个领域的技术模块和特性有了充足的了解(其实非常浅嗯)。在一次无意间的检索中 ,以CAPTCHA 为关键词又重新搜到了这个项目(原来 Epic 真的可以免费领取游戏!用了老半年的 Epic Games Launcher 都没发现同一个客户端还有个游戏库的选项)。

我翻了翻“评论区”,情况不太乐观- -不少玩家反应 CAPTCHA 阻挡验证的问题,但维护者疏于忙碌,暂时无暇升级项目,同样的报错议题已经累积的一个月之久。车祸现场如下:
当时想着自己对人机挑战略知一二,便翻起了项目源码,看看大佬是如何梳理整个业务流程的。
但很遗憾……这项工作持续不到 10 分钟我就放弃了。我用成分分析工具解剖了核心业务类EpicgamesClaimer() 后发现,这个看似朴实无华的玩意,竟然塞进了 59 个类方法,还放入了意义不明的 async 事件循环,大概情况如下图所示:
(os:没有讥讽的意思,这里表露的只是我当时的第一反应,确实没见过这样的场面-。-
至此,一个重头构写「Epic免费人」的想法诞生了。但起初,我是奔着 hCaptcha challenge 去的,刚积累了这么多料子,正好遇到一个可以练手的挑战,不趁热打铁怎么行,于是我在该楼层下烙下一句“问题不大”后,创建了一个空白仓库,开始设计新项目的技术模型。
🤦♂️emmm…现在是北京时间 2022-01-29 01:23 博客写到这的时候发现这个仓库被封掉了……真是一言难尽。
Little changes
🍜 分享一些本项目中有关「人机挑战」的重点与难点。
Undetected Flow
📋 要处理 hCaptcha challenge 首先要有可以隐藏控制特征的自动化技术。
Preview
如果读者和 CAPTCHA 打交道的时间不够长但又刚好会一点浏览器自动化技术,你可能会抢答“这个反爬用普通的伪装过不去,必须用浏览器自动化!”,大概率是这样,但不够精确,应该改成“无定向的浏览器自动化”技术。
咱们做个小测试,分别以手动,编写 selenium 脚本,以及 selenium headless 脚本的形式访问这个链接 https://bot.sannysoft.com/ 。
手工打开的浏览器是我们所谓的“正常特征”,如下图所示(页面中还有很多的参数项,篇幅有限就不多展示了)。
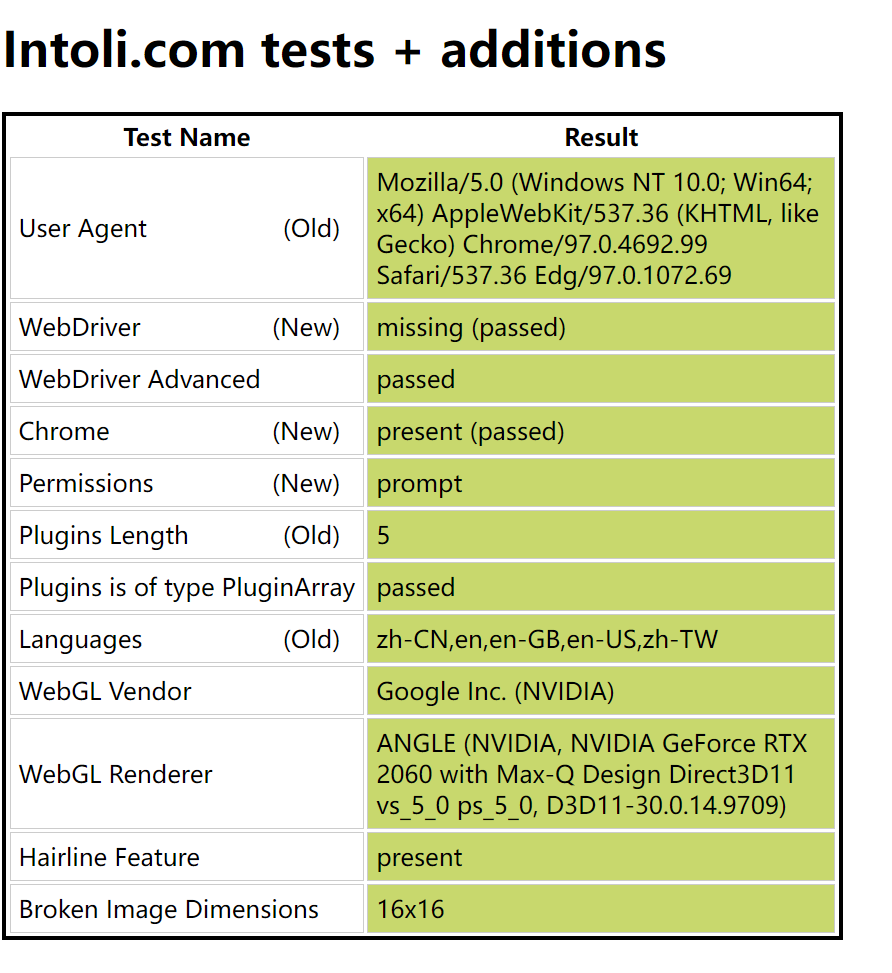
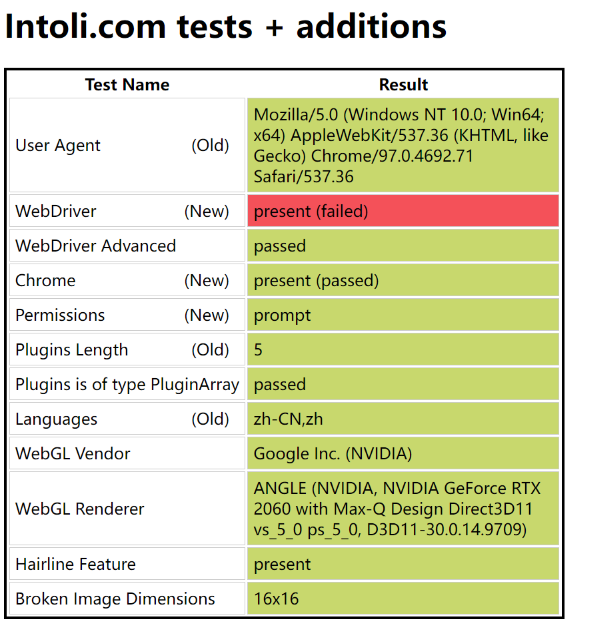
使用默认参数启动的浏览器会有很多被标红的“异常特征”,如下图所示(页面中还有很多的参数项,篇幅有限就不多展示了)。
接下来,您可以复制如下代码进行无头访问,并以截图的形式检查回馈参数:
import os
from selenium.webdriver import Chrome, ChromeOptions
from webdriver_manager.chrome import ChromeDriverManager
def demo():
path_screenshot = "stander_headless.png"
options = ChromeOptions()
options.headless = True
with Chrome(ChromeDriverManager(log_level=0).install(), options=options) as ctx:
ctx: Chrome
ctx.get("https://bot.sannysoft.com/")
ctx.save_screenshot(path_screenshot)
os.startfile(path_screenshot)
if __name__ == '__main__':
demo()
测试结果截图如下:
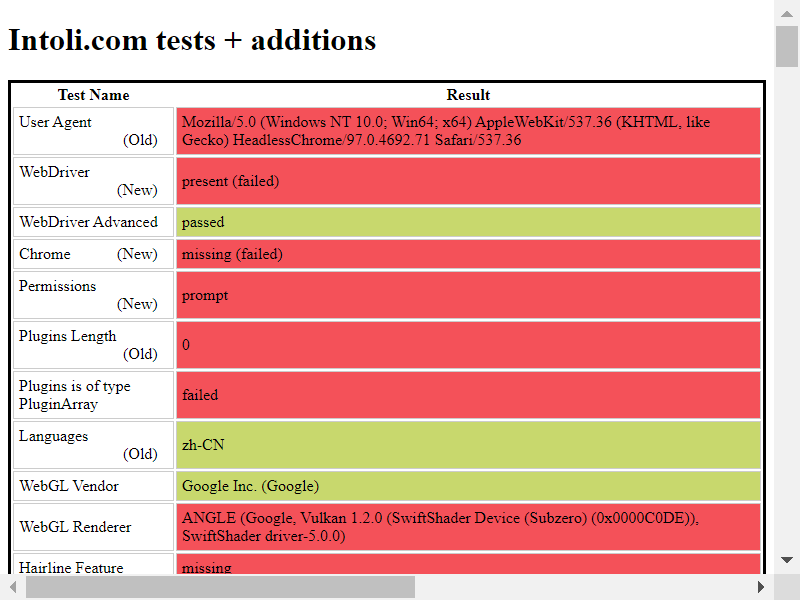
是不是感觉很惊讶?还在以为其实浏览器自动化可以胜任爬虫的工作吗?
Selenium Documentation 中也明确说道,浏览器自动化工具用于爬虫业务并不符合最佳实践的要求,因为 WebDriver 的特征检测技术老早就普及使用了,几乎是和 selenium 同个时代的技术。
这时候有的读者可能会说,我们可以添加 ChromeOptions() 呀。好的,现在尽你所致,把你知道的所有参数都加上,再次访问。你也许会发现表格上的“正常特征”会越来越多(截图展示的仅是部分参数),这是一件好事吗?我们先按下不表,但你是否发现,无论你怎么努力,表格中 WebDriver 一项始终是“异常的”。好的,现在我明确告诉你,截图中的 WebDriver 是识别控制流量的关键指标。
这也解释了为什么处理 CAPTCHA 要先解决 undetected flow 的问题。现代化的人机验证都会通过前置的 JavaScript 脚本捕获用户的页面控制轨迹,一旦驱动的 WebDriver 指标亮起,你的一切后续操作都是徒增功耗,即使人机挑战“通过”,你也无法获取正确的身份令牌。
Solution
兜了这么大的圈子,这里要介绍一个在业界几乎没有竞品的项目 undetected-chromedriver。通过它,我们可以安全地隐藏驱动控制特征,将我们所有的业务逻辑安全地送到人机挑战页面。关于这个项目的特性我会另开博客详细介绍,其中大有门道。
此处,你可以通过如下引导快速复现一个“无踪环境”,并得到驱动测试参数。
pip install undetected-chromedriver==3.1.3
# -*- coding: utf-8 -*-
# Time : 2022/1/27 6:02
# Author : QIN2DIM
# Github : https://github.com/QIN2DIM
# Description:
import os
from undetected_chromedriver import Chrome
def demo():
path_screenshot = "undetected_headless.png"
ctx = Chrome(headless=True)
try:
ctx.get("https://bot.sannysoft.com/")
ctx.save_screenshot(path_screenshot)
finally:
ctx.quit()
os.startfile(path_screenshot)
if __name__ == '__main__':
demo()
undetected-chromedriver 无头启动
可以看到,我们在不指定任何参数的情况下,
WebDriver指标是正常的。
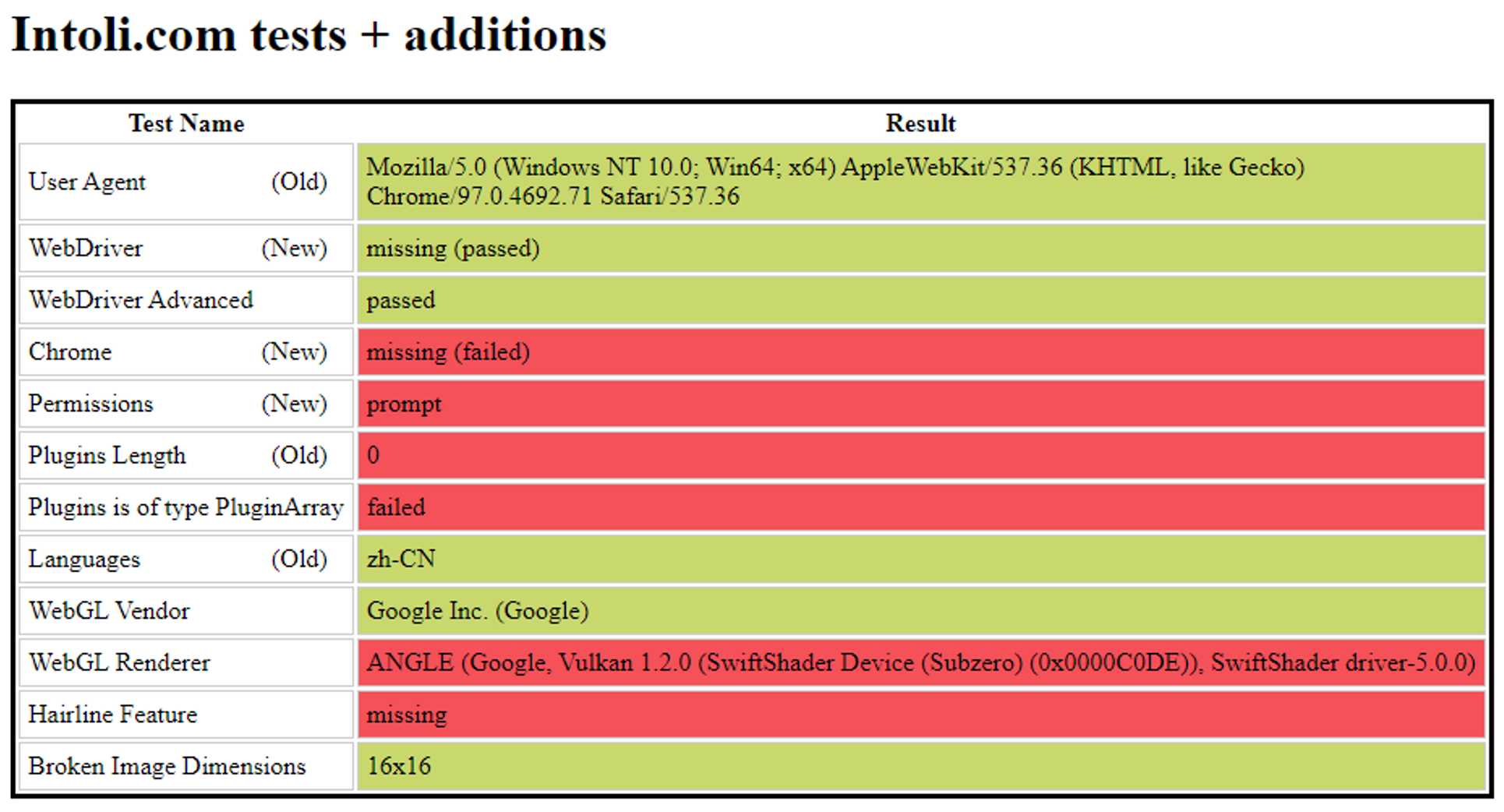
undetected-chromedriver 正常启动
在正常启动且不指定任何可选参数的情况下,
WebDriver指标是正常的,不仅如此,其他所有的主要特征都通过了验证,和我们手动打开网站得到的结果几乎是一样的。

Trouble
到此阶段,我们可以回顾一下 EpicgamesClaimer 项目中遇到的第一个困难,那便是整个项目与 Puppeteer 强绑定,维护者几乎为每一个原子操作都做了修饰封装,而 puppeteer(也可称 pyppeteer) 与 Selenium 一样都是主流的自动化测试框架,并不具备隐秘特征的能力。所以,维护者几乎只能基于 pyppeteer 的生态寻找类似的解决方案,或基于 pyppeteer 底层特性寻找突破口,或选择 undetected-chromedriver 嫁接开发。但无论选择哪一种,代价都是极其惨痛的。
Threat Level
📋 正所谓「知己知彼百战不殆」,在硬刚人机挑战之前,我们得先知道 hCaptcha challenge 的运作逻辑,以及「验证通过」「威胁等级」如何定义,我们才能优雅地通过测试,并将挑战模块无缝地衔入到主线业务中去。
感兴趣的朋友可以参考一下 M. I. Hossen 等人的攻击方法 doi: 10.1109/SPW53761.2021.00061.
文章里详细介绍了人机挑战的前世今生以及当下主流的人机挑战形式;总结了 hCaptcha 差异特性,并简要说明了一些 element 的获取思路与模型训练的实验步骤。点击快速打开 PDF 预览文章。
preview
其中有一些值得注意的现象,在论文摘要中作者写道:
We evaluate our system against 270 hCaptcha challenges from live websites and demonstrate that it can solve them with 95.93% accuracy while taking only 18.76 seconds on average to crack a challenge. We run our attack from a docker instance with only 2GB memory (RAM), 3 CPUs, and no GPU devices, demonstrating that it requires minimal resources to launch a successful large-scale attack against the hCaptcha system.
在正文中作者详细解析了数据组成:
…Our deep learning classifier (the Solver) takes 3.79 seconds to classify the images (usually 9) in a challenge, on average…
然后奉上了图3,作者将业务耗时拆分成浏览器自动化的耗时以及图像分类任务的耗时,可以发现浏览器控制用的时间占了一次业务中的绝大部分(符合常识)。
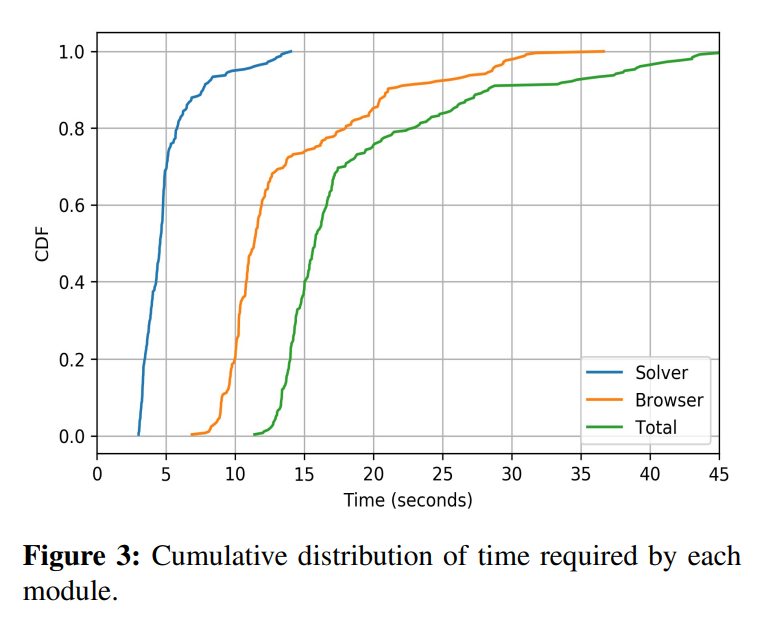
但其实我是蛮疑惑的,首先是这个 3.79s 的数据是如何算出来的。我们处理 hCaptcha 一般有两轮验证一共 18 张图而这里用了 usually 9;其次,当我们的威胁等级足够低时,我们甚至会在激活 checkbox 后跳过人机挑战。
然后是 18.76s 的平均总耗时其实也是实验条件下的结果,至少拿 Epic 更新身份令牌的行为来说,我们启动「挑战者驱动」可能就要用 15s 。文章中的浏览器操作耗时的具体行为包括「初始化挑战(进入页面加载页面)」「与 checkbox 交互并激活挑战」「提交挑战」以及「验证挑战是否成功」,忽视了最耗时的图片下载过程,其次在验证挑战是否成功环节,真实业务场景需要进行非常复杂的元素断言,而在实验环境下几乎只用判断按钮是否能继续点就可以(排除判断)说明挑战是否成功。
We found that hCaptcha often repeats images across different challenges. We computed the MD5 hashes of 48330 images collected from the hCaptcha challenges during our analysis and identifified 9854 redundant images belonging to 1985 sets of identical images.
作者后文说道,他们发现挑战中经常遇到重复的图片,于是用了感知哈希判断在多伦测试中攒下来的图片中有多少重复的。真够狠的爬了五千多次。。
Solution
Synergy framework
📋 协同框架立大功!
preview
根据上文可知,CAPTCHA 一般都设有时间限制,一段时间内未通过测试页面元素就会自主刷新过时。我们知道,下载图片恰巧是个经典的网络I/O耗时场景。因此,我不由地想到利用协程技术缩短人机挑战的耗时,提高容错。
Solution
- 轻量可移植的协同任务框架
在本项目 utils 中存放着一个轻量化的 Synergy framework ,其核心业务代码可见 CoroutineSpeedup()。打上 monkey 鸡血补丁后,协同任务开始运作。
- 使用
gevent而不是async
gevent 是作者编写 Python 协程的常用方法。相交于 async ,使用 gevent 能够更自如地控制模块的布局与业务的上下文联系,不必为了接口的兼容关系割裂本该完整的函数体;从整体上看,这也能让实现同一逻辑的代码更加规范整洁雅观;从 Python 新手来说,gevent 不需要改动原始代码的逻辑就能实现协同,这给还未深刻理解 async 的朋友来说降低了很多的理解门槛。借知乎网友的话就是“手动挡和自动挡的区别”,个人觉得是非常真实了。但此处也有个坑,也是本项目目前遇到的最大技术难题,后文细说。
- 45路公交与自行车
原先的 for loop 循环下载一轮挑战的 9 张图片的总耗时为每张图片下载耗时之和,而在协同任务中,总耗时为单图的最长耗时,由此极大缩短数据集拉取的时间。
在 GitHub Actions 里这是一种体感差距,几乎瞬间拉取,如下图所示。
而在国内网络条件下,这就是判定挑战能否开启的守门员指标。从本人的网络条件来说,在不开启代理的情况下,300MB 带宽跑满拉取位于国外服务器上的图片,每张图花费将近 10 秒的时间,如果不引入协同下载的概念,光是下载图片我们都要干等一分半,而同样的时间,已能在工作流中结束一次人机挑战了。