
Preview
Google SeaNet 的 Andrea Agostinelli, Timo I. Denk 等人于 2023年1月26日发布了 《MusicLM: Generating Music From Text》。在项目演示页中,我们可以看到 MusicLM 惊人的 prompt to music 能力,模型输入不再受限于传统的 TextPrompt,用户可以提供更加丰富的音乐元素让 AI 完成剩余的作曲任务。
Abstract
MusicLM 是一个从文本描述中生成高保真音乐的模型,例如:平静的小提琴旋律伴着扭曲的吉他旋律 。MusicLM 将有条件的音乐生成过程作为一个层次化的序列到序列的建模任务,它生成的音乐频率为24kHz,并在几分钟内保持一致。实验表明,MusicLM 在音频质量和对文本描述的遵守方面都优于以前的系统。此外,MusicLM 可以以文本和旋律为条件,因为它可以根据文本说明中描述的风格来转换口哨和哼唱的旋律。为了支持未来的研究,Google 公开发布了MusicCaps,这是一个由「5.5K 音乐-文本对」组成的数据集,其中有音乐家提供的丰富的文本描述。
Demonstration
Music to Music
首先,你可以提供 music 形式的输入,例如:哼唱的旋律录音,或是十几秒的吉他即兴演奏,模型会根据主旋律延拓剩余的部分完成 30s, 60s 甚至几分钟的具有叙事风格的完整曲目。
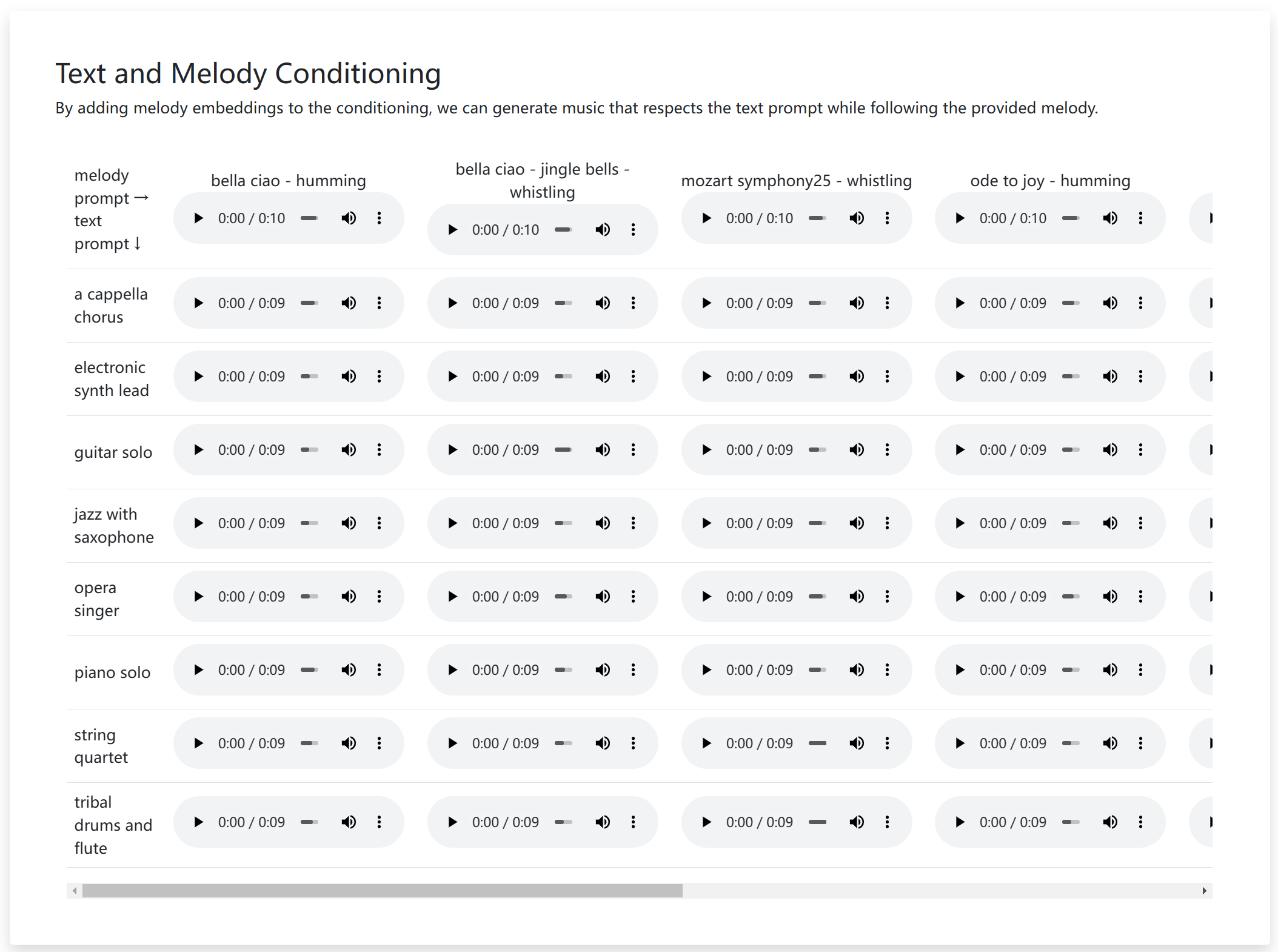
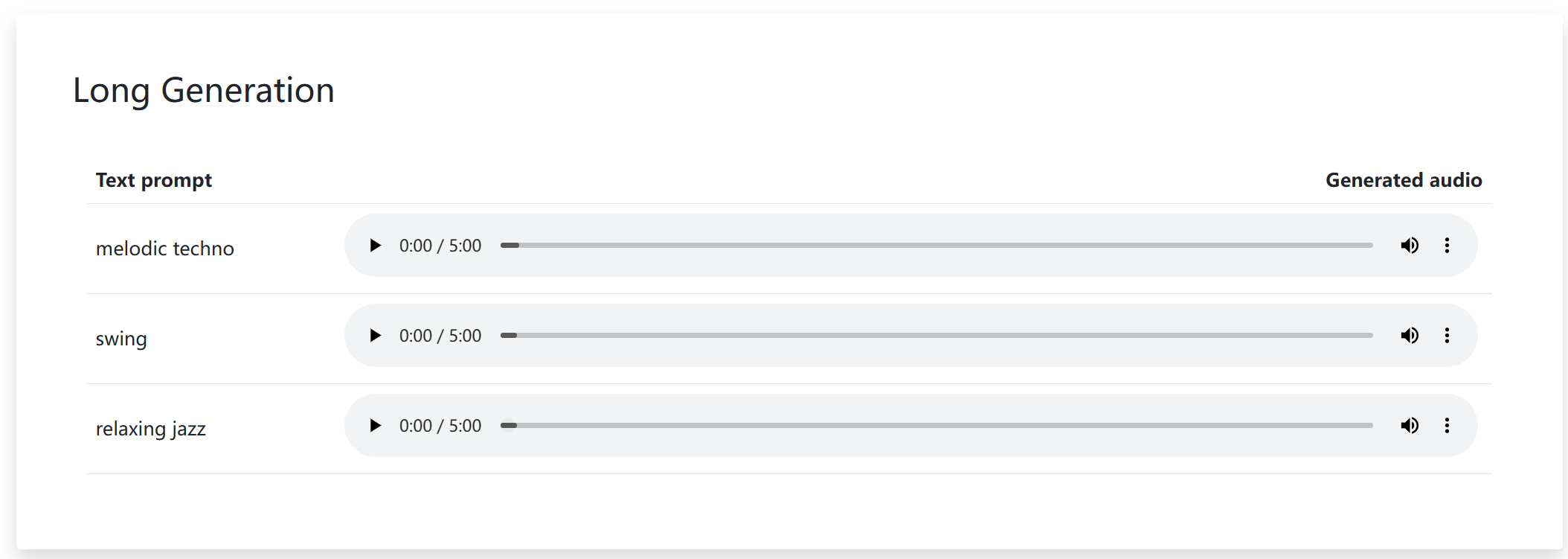
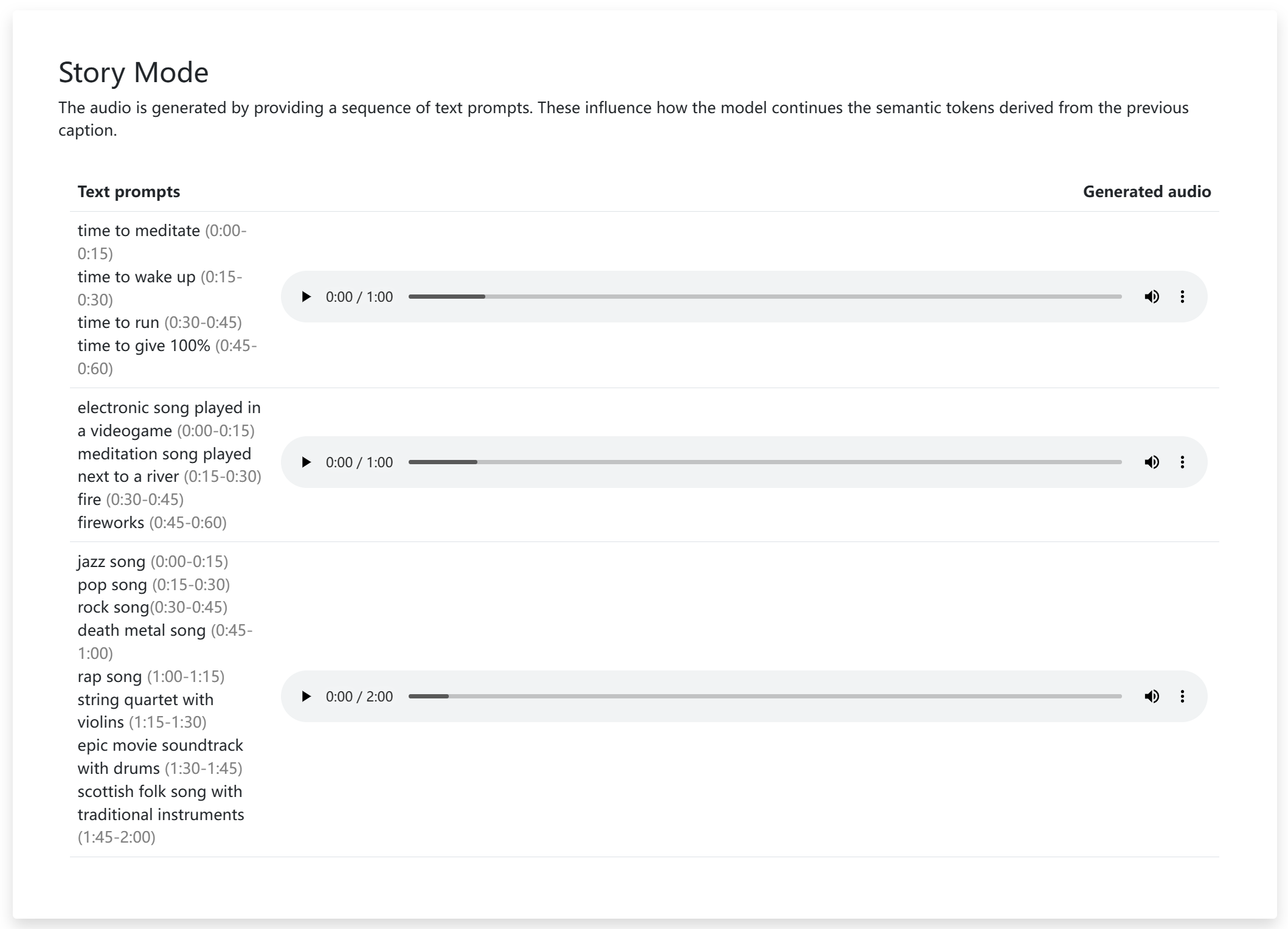
此外,该功能还能将视频创作中的背景音乐拓展成无限循环音乐(再也不用到 AU 中单独调了累),可以以某种流派的风格改编乐曲,在未来有可能演化成一个无情的扒谱机器人。
Image to Music
其次,你可以提供 image 形式的输入,可以是生活中抓拍的精彩瞬间,也可以是景区合影,甚至可以是一副抽象派作画。模型首先会「看图说话」概述图像内容并以文本的形式输出,即,image to text,而后模型便可输出一首特定主题风格的「可以描述此情此景的背景音乐」。
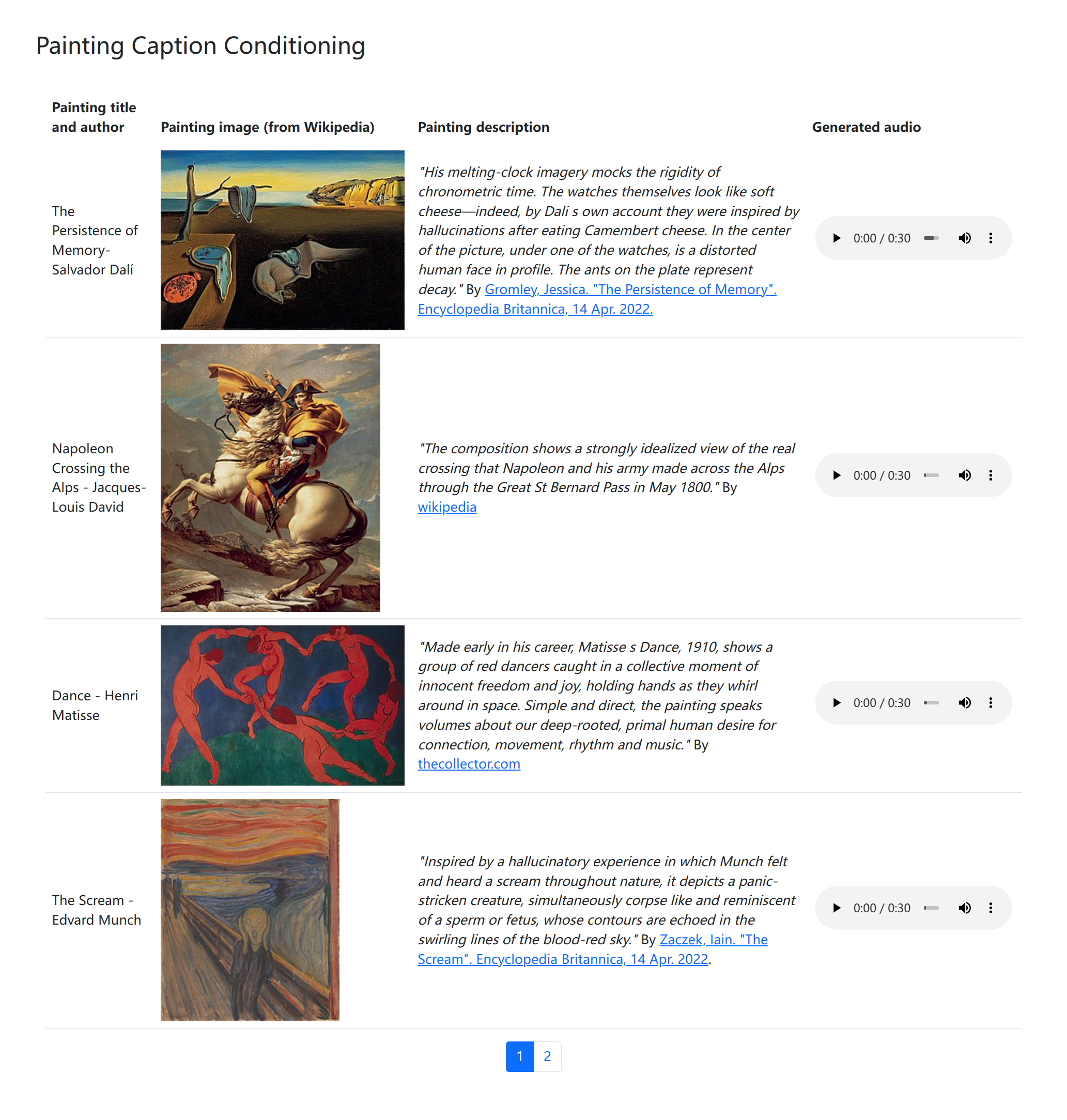
此外,可以指定 Title/Theme,也可以修改模型的概括内容然后重新生成音乐。
Text to Music
接下来是传统内容的横向突破,用户可以在「初始化后」以一种交互的形式不断地给 AI 提供需求,例如,加入爵士乐,合唱介入,弦乐四重奏等等。MusicLM 在 text 形式的输入中提供了更加丰富的关键词参数。你可以在 prompt 中指定音乐家,流派,地点,风格等等。
Conclusion
总得来说,这些特性是可以排列组合的,可以在一个完整的工程中一并使用,它们可以被用在时间轴上的各个位置,对于专业的作曲家来说,它可能仅是一个灵感来源工具,尚未达到直接参与乐曲创作的水平。
对华语乐坛流行音乐来说,在曲目形式以及和弦排列组几乎穷尽的大背景下,把 AI 作为灵感提供工具可能会不错的效果。但目前来看抖音神曲和 AI 完全创作的流行音乐我都欣赏不来,前者属于陈俗烂调,完全不想再听一遍,大都只能用副歌做个十几秒短视频的 BGM。而后者则是物理意义上的难听,音质太差,目前业界最先进的用户接口都有这个瓶颈,必须「人机结合」才能做到可用的程度。
最后,SeaNet 强调未来的工作可能会集中在歌词的生成上,同时改进文本调节和声乐质量;另一方面是对高级别歌曲结构的建模,如引子、诗句和合唱;而以更高的采样率对音乐进行建模是更高阶段的目标。