
更多信息请参见 GitHub Repository
前言 🤦♂️
🎉 本人有幸作为项目负责人参加 2020 中国大学生计算机设计大赛,并拿下了大数据实践赛全国一等奖。
🧐 做这个程序的初衷垂直~无意中看到了某个设计方向的作品,感触很深 ;本科生能独立完成这样的作品,真是太震撼了!嗯我说的就是“红楼梦信息交互设计”的华科小姐姐团队,真正的面向薪资编程!
🛒 于是便有了一个收藏并展示该类比赛优秀作品的想法,于是本人点开官网后发现最新的作品展示还要追溯到 2015 年-……行吧那就撸起袖子自己写了一个自动化采集程序,该程序会自动化采集作品数据,并生成永久访问链接,展示的信息会经过数据脱敏,仅放出项目 idea 以及作品申报信息,供大家考古学习。
🚀 总而言之该脚本主要功能就是采集作品信息和拷贝作品信息。我会在均衡程序的鲁棒性后,引入垂搜引擎,帮助使用者检索 同质idea 以及 同质优秀参赛作品。
🍵 最终的作品展示方式,本人会慎重考虑。如果官方工作人员觉得不太妥,可以私聊本人喝茶[嗯!道歉是认真的!]如果觉得本项目有望吸引更多的年轻人参赛施展才智,提高竞赛的知名度与含金量,可以私聊本人喝咖啡~
快速上手 🐱🏍
Clone 项目,进入
main.py,按照说明书合理调用API,运行程序即可调度爬虫采集数据。
配置运行环境
部分 API 使用 python3 + selenium 的采集方案,且该脚本仅支持 Chrome 驱动,请将您的谷歌浏览器更新到最新版本。
python -m pip install --upgrade pip &&
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple采集作品信息
app.run_crawl_to_capture_workData(work_id: str or list,power: int)- work_id:作品编号,支持单个字符串输入以及 List 多个字符串输入
- 【1】传入单个作品编号;
- 【2】传入包含多个作品编号的列表;
- 【3】传入空字符串或不传入
work_id,则默认采集 BASE 中所有的 ID 对应的作品数据(目前有 4076 个数据在库),此时请适当调高协程功率
- power:协程功率,
power∈[1,∞),脚本内置弹性协程队列,此处可随意设置。
- work_id:作品编号,支持单个字符串输入以及 List 多个字符串输入
- 运行后会在
/dataBase/目录下生成合成.csv文件 - 从 config 配置文件中打印变量
title即可查询信息键
from MiddleWare import app
from config import *
if __name__ == '__main__':
id_list = ['75945','68589']
# app.run_crawl_to_capture_workData(work_id='72862',power=30)
app.run_crawl_to_capture_workData(id_list, id_list.__len()__)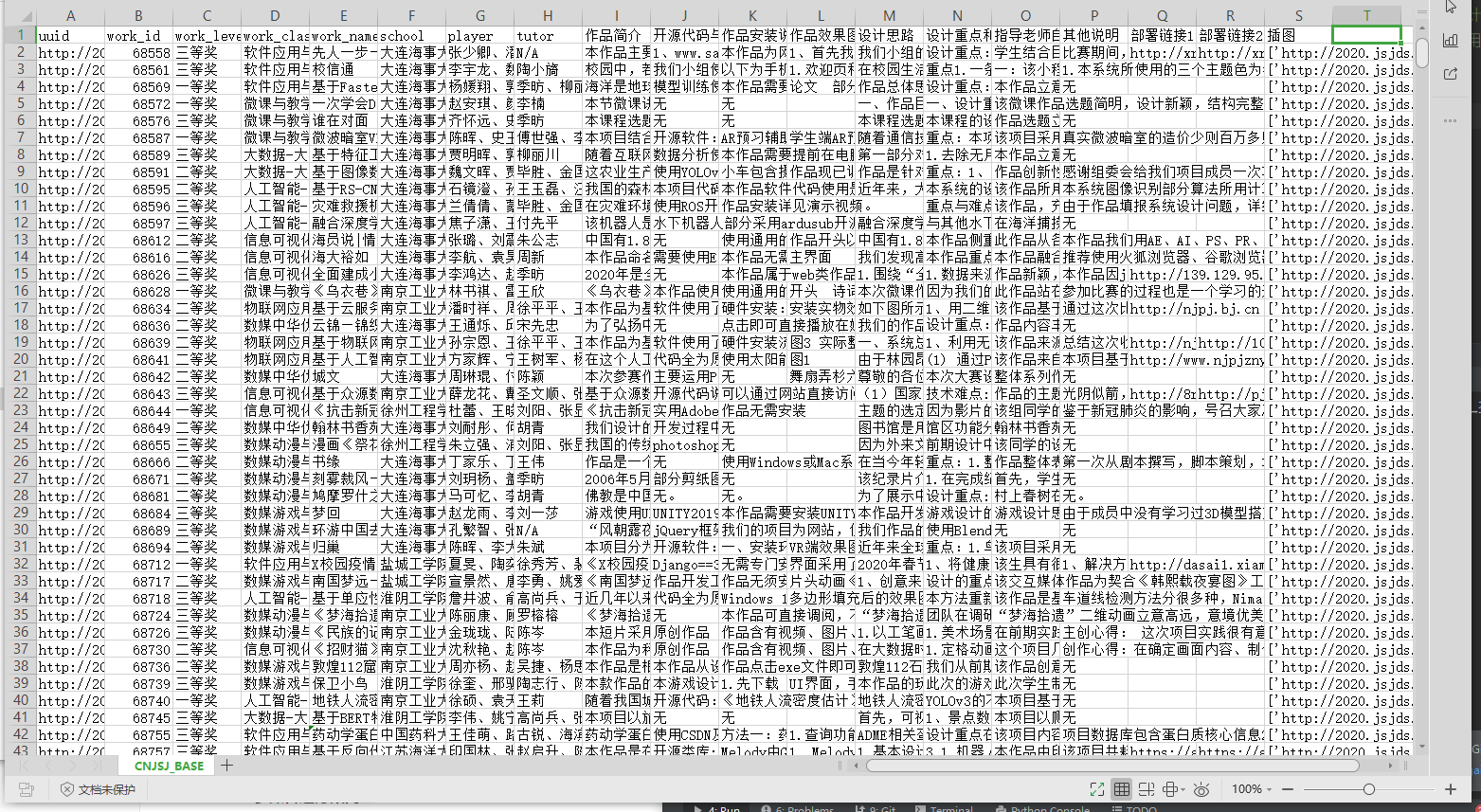
拷贝作品信息
app.run_crawl_to_capture_workData(work_id: str or list,power: int=4)- work_id: 作品编号,支持单个字符串输入以及 List 多个字符串输入,参数传递方案同上。
- power: 协程功率,
power∈[1,∞),脚本内置弹性协程队列,此处可随意设置。
运行后会在
/dataBase/BACKUP/目录下生成以作品编号命名的.mhtml文件,该格式网页文件封装了源所有的文本及插图附件,部分作品内容精彩,文件体积占用较大。- 注:safari 可能会打不开这种格式文件。
- 该功能使用 Selenium(base on Chromedriver) 采集,请确保电脑上安装了最新版本的谷歌浏览器。
- 该功能需要联网使用,请确保网络通畅。
from middleware import app
from config import *
if __name__ == '__main__':
app.run_crawl_to_backup_data('72862',power=1)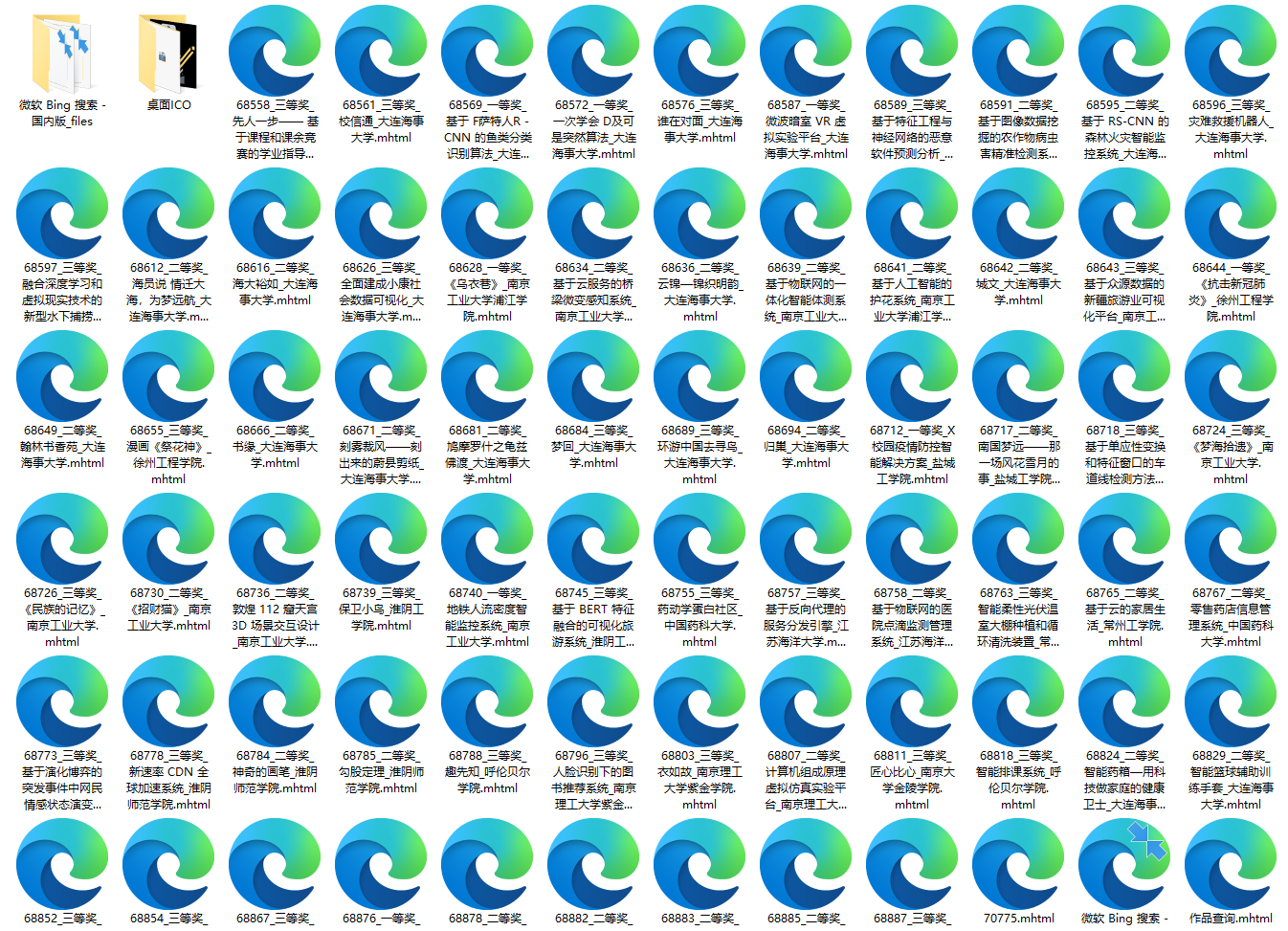
API
在从 MiddleWare 中导入 app,即可调用脚本功能,别忘了调用 config 配置文件设置全局变量~
from middleware import app
from config import *作品查询~学校成果
app.get_school_psar(school_name: str,save: bool)- school_name:学校名称。这里不支持模糊匹配,请输入全称!
- save:保存输出。默认为 False;建议为 True,运行后会在
/dataBase/PSAR目录下生成对应学校的分析结果,文件格式为.json,信息键仅包括获奖信息以及作品链接。文件会自动打开。
from MiddleWare import app
from config import *
if __name__ == '__main__':
app.get_school_psar(school_name='华中科技大学',save=True)/华中科技大学_分析报告.json
{
"华中科技大学": {
"成果概要": {
"一等奖": 2,
"二等奖": 8,
"三等奖": 2
},
"作品细节": {
"一等奖": [
{
"http://2020.jsjds.com.cn/chaxun/?keys=72849": "皖江之阴,青山之阳;青阳有腔,放遇一欢。"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=72862": " 红楼梦·可视化赏析信息交互系统"
}
],
"二等奖": [
{
"http://2020.jsjds.com.cn/chaxun/?keys=72750": "Limfx科研博客"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=72764": "梦·山海"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=72795": "济世方舱"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=72796": "山哈彩带"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=72800": "敦煌·梵音"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=72821": "放大镜下的昆虫世界"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=72822": "九华折扇——数字化非遗文化信息可视化设计"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=74879": "别让它灭绝"
}
],
"三等奖": [
{
"http://2020.jsjds.com.cn/chaxun/?keys=72783": "皮影传承,戏中人生"
},
{
"http://2020.jsjds.com.cn/chaxun/?keys=72799": "希冀"
}
]
}
}
}作品查询~奖级AND赛道
app.find_works_by_level(level: str,class_: str)- level:作品等级。这里需要规范输入,只能输入以下选项
一等奖、二等奖、三等奖
- class_ :作品赛道。这里支持模糊匹配。在
/dataBase/TPTDP/class_name.txt中有C4-2020所有赛道的全称
- level:作品等级。这里需要规范输入,只能输入以下选项
- 食用说明:
level和class_都不是必选参数,比如只想知道一等奖的所有作品,只需传入level即可,class_可不传或传入空字符串。
from MiddleWare import app
from config import *
if __name__ == '__main__':
# app.find_works_by_level(level='一等奖', class_='大数据')
# app.find_works_by_level(level='', class_='人工智能')
app.find_works_by_level(level='一等奖', class_='')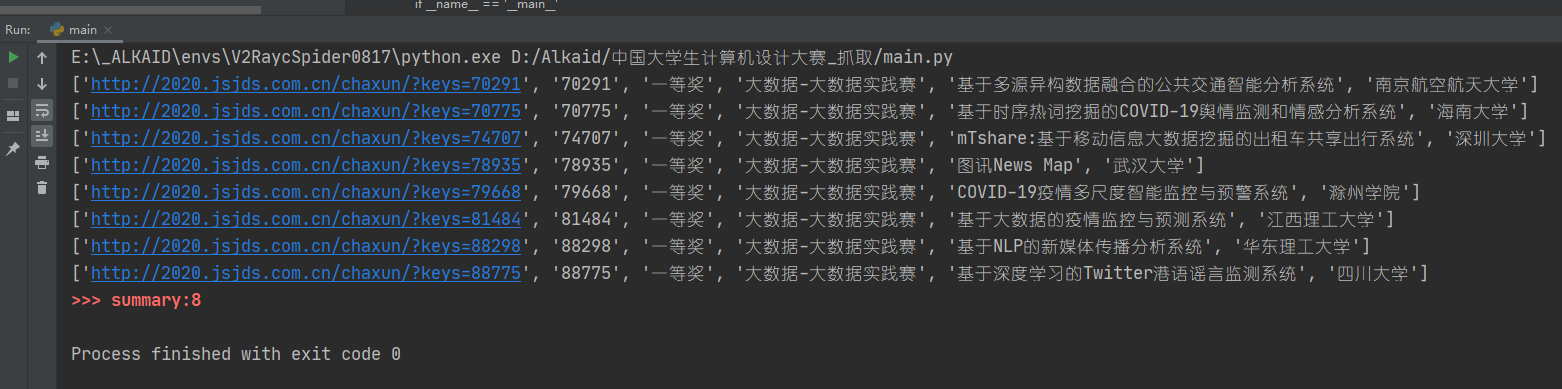
作品查询~比赛摘要
app.get_summary()打印决赛成绩概况

作品查询~链接直达
app.find_works_by_id(key: str, goto: bool)- key: 作品编号,仅支持单个字符串输入
- goto:是否打开网页。若为 True,则使用默认浏览器打开作品首页
- 运行后会在
/dataBase/PSAR/ASH.json中留下临时文件
from MiddleWare import app
from config import *
if __name__ == '__main__':
app.find_works_by_id('72862')works_id数据加载
- 由于表数据结构比较乱,我已经写好了一个全局 load id 的函数,使用方法也很粗暴,调用该函数并传入
spider_key,即可获取含表头的在库id列表。获取列表后使用切片去除表头候即可获得干净的数据~ - 因为合成BASE文件有点大,故使用
csv.field_size_limit()捕获数据流。
# config.py
def load_data_from_id_set(mode) -> list:
"""
data_set = title
:param mode: 截取模式,
spider_key : 联采
str:works_id : 该作品编号对应的数据
list:works_id :
:return:返回表头+数据,使用切片[1:]截出数据集
"""
# 当爬虫程序使用此函数时,并传入‘spider_key’口令,函数执行特殊命令,返回含表头的作品编号 List[str,str...]
# 返回的列表里包含了所有在库的works_id,既当爬虫爬虫程序传入该口令时,将采取所有作品信息
with open(id_fp, 'r', encoding='utf-8') as f:
csv.field_size_limit(500 * 1024 * 1024)
reader = csv.reader(f)
data = [i for i in reader]
if mode == 'spider_key':
# 清洗数据
return [i[1] for i in data if i[1] != 'N/A']- 食用方法
from MiddleWare import app
if __name__ == '__main__':
# 返回无表头 id 列表
id_flow: list = app.get_all_works_id()
# 数据预览
print('id池大小:{}'.format(id_flow.__len__()))注意事项 ❗
- 工程文件中的
/dataBase目录下存放了脚本核心BASE文件,请勿随意挪动或删除文件,否则会出大问题! config.py中可以自己调整的参数并不多,请勿随意改动其中数值,否则也会出大问题~
更新日志 📋
2020.09.06
- 已将所有
2020-MTH作品申报信息离线封装 - 将采集功能都封装进
app.py里,所有功能都可通过该模块调用 - 添加语雀同步文档,解决部分地区图文显示异常的问题
- 项目除虫,增加了垃圾回收机制
TODO 📈
- 搭建类BLOG前端,开放接口映射优秀作品文件
- 服务器部署
- 引入鲁棒均衡模组
- 添加垂搜引擎,提供API接口