
Preview
在开始本教程之前,请确保你已经注册了谷歌账号,能够科学上网,并且了解 Colaboratory 的基本功能。
如果你是从未尝试过 Stable Diffusion 的新手用户,我们提供了本方法,让你轻松上手。如果你拥有足够强大的 GPU 计算能力、内存和硬盘空间,你还可以将 Stable Diffusion 部署到本地,这将使整个生产过程更加安全可靠。
本教程会带你领略 AIGC-2023 的曼妙世界,以 ChilloutMix & LoRA 基本模型为切入点,帮助你踏入 AI 应用领域。
Quick Start
前往网站 Colaboratory。
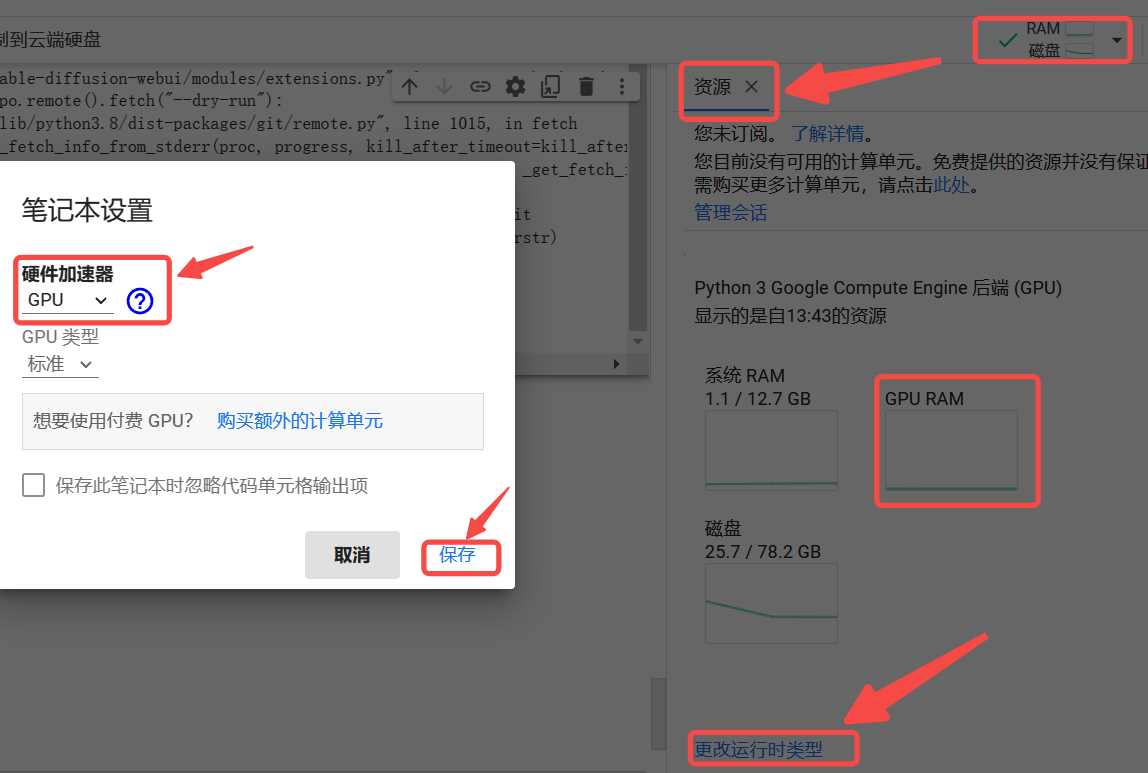
点击「查看资源」,进入「更改运行时类型」设置,选择「硬件加速器」,并选用 GPU。
等待连接成功后,重新查看资源信息。如果发现出现了 GPU RAM 图表,说明成功启用了 GPU 加速器。
免费用户默认使用 CPU 实例,但是对于 AI 图片生成等复杂任务,CPU 的算力已无法胜任。也即,必须启用 GPU 才能顺利运行和部署 Cloud-based Stable Diffusion。
部署脚本
回到 Colaboratory,新建代码块,贴入如下代码安装依赖,预计耗时 3~5 分钟。
!pip install --upgrade fastapi==0.90.1
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
!git clone https://github.com/yfszzx/stable-diffusion-webui-images-browser /content/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser
!git clone https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN /content/stable-diffusion-webui/extensions/stable-diffusion-webui-localization-zh_CN
!git clone "https://github.com/canisminor1990/sd-web-ui-kitchen-theme" /content/stable-diffusion-webui/extensions/kitchen-theme
!curl -Lo chilloutmixni.safetensors https://huggingface.co/nolanaatama/chomni/resolve/main/chomni.safetensors
!curl -Lo ulzzang-6500.pt https://huggingface.co/nolanaatama/chomni/resolve/main/ulzzang-6500.pt
!mv "/content/chilloutmixni.safetensors" "/content/stable-diffusion-webui/models/Stable-diffusion"
!mv "/content/ulzzang-6500.pt" "/content/stable-diffusion-webui/embeddings"
%cd /content/stable-diffusion-webui
!COMMANDLINE_ARGS="--share --disable-safe-unpickle --skip-torch-cuda-test --no-half-vae --xformers --reinstall-xformers --enable-insecure-extension-access" REQS_FILE="requirements.txt" python launch.py安装完成后,控制台会输出部署到 Gradio 的 stable-diffusion-webui 的公共访问链接,该链接有效期为72小时,如下图所示。请新建一个标签页访问链接。
请注意,不要关闭此 Shell 控制台或 Colab 标签页,否则 WebUI 服务将直接中断。

输入咒语
访问你的 Gradio 控制台,进入 txt2img 炼金炉,在上方 prompt 输入如下咒语:
(realistic, photo-realistic:1.37), (8k, RAW photo, best quality, masterpiece:1.2), pink eyes, cute, ultra-detailed, heart-shaped pupils, physically-based rendering, ultra high res, front lighting, looking at viewer, photorealistic, realistic, solo, photorealistic, best quality, extremely detailed face, extremely detailed eyes and face, beautiful detailed eyes, absurdres, incredibly absurdres, Messy hair, floating hair, green hair, close-up, portrait, 在下方 Negative prompt 输入如下咒语:
EasyNegative, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand,backlight, (worst quality, low quality:1.4), watermark, logo, bad anatomy, nude, topless, fat,EasyNegative,以上两个提示语的作用顾名思义。本文提供的内容仅供参考,您也可以在部署后自行探索,或者参考其他人留下的攻略。
这里有必要指出的 demo 中提到的关键内容,如「消极提示」中的 bad hand,fingers,extra fingers等词旨在抑制“花式输出”,而「积极提示」中的 8k,ultra-detailed则用于获取高度复杂的画面细节。
以下是其他参考参数:
Handler:
Sampling method: DPM++ SDE Karr
Sampling steps: 20
Width: 512
Heigh: 768
Batch count: 1
Batch size: 1
CFG Scale: 7.0
Seed: -1
Script: None
Checkbox:
Restore faces: False
Tiling: False
Hire.fix: True
Hires.fix:
Upscaler: Latent(bicubic antialiased)
upscale by: 1.05
Hires steps: 15 # 10~20
Denoising strength: 0.7 # 0.4~0.7点击「Generate」开始念咒语!!!
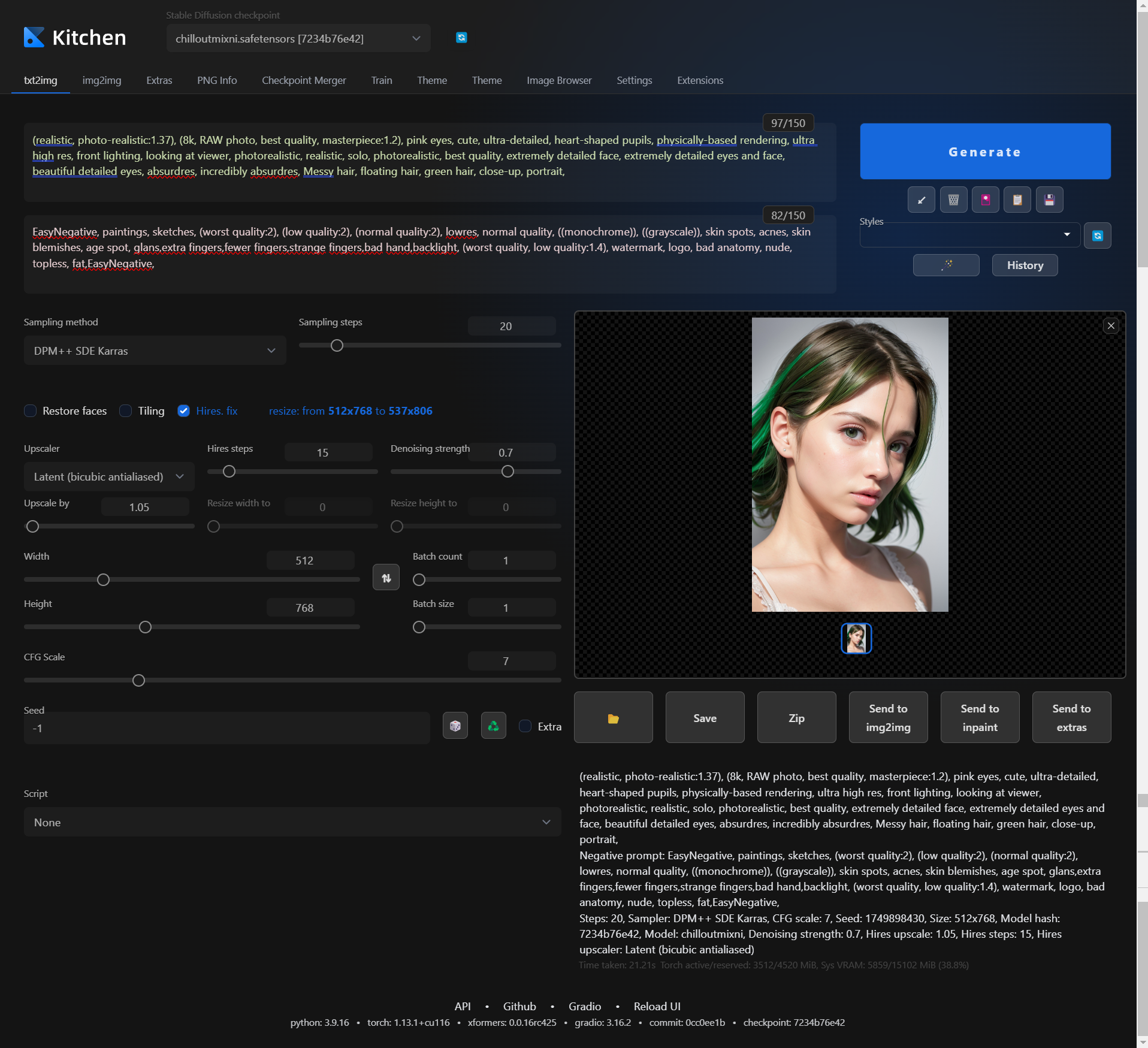
预览输出
点击图片渲染区的 「Save → Download」将图片缓存到本地目录。

下面有更具可玩性的选项供您选择:
- 如果您输出了组图,可以勾选多张图片并选择「Zip」来打包下载。
- 如果您对某张输出结果特别满意,可以选择「Send to img2img」,这样您就有了更多选择,例如进入 ControlNet 的神奇世界,基于人物骨骼进行二次创作。
- 如果您是专业画手,可以进入「Send to inpaint」页面,对 AIGC 的产出进行二次编辑。
- 最后,您可以选择「Send to Extras」,增强图片的细节,增加像素量或者延续创作风格,生成新的图片。
本篇博客不讨论 Prompt 关键词及各种模型抑制参数的含义,如有兴趣,欢迎在 Google 上深入搜索。
军火展示
我使用了另外的咒语输出了 8 张图片,可用率100%,效果还不错。
值得一提的是,如果您在控制台中进一步调整 upscale 参数,为图片填充像素量,使得单张图片输出大小在 2~5MB 范围内,图片信息量将提高到第一个甜点区。








| Output | Prompt |
|---|---|
 | a portrait of an old coal miner in 19th century, beautiful painting with highly detailed face by greg rutkowski and magali villanueve |
 | portrait photo of a homeless , color, Martin Schoeller, serious eyes, perfect eyes, cinematic, 80mm portrait photography, dramatic lighting photography, national geographic, portrait, photo, photography, Stoic, cinematic, 4k, epic, detailed photograph, shot on kodak detailed, bokeh, cinematic, hbo, dark moody, volumetric fog, minimal artifacts, inspired art by p. craig russell |
 | (8k, RAW photo, best quality, masterpiece:1.2), (realistic, photo-realistic:1.37), ultra-detailed,full body,1 girl, solo,beautiful detailed sky,detailed tokyo street,night,beautiful detailed eyes,beautiful detailed lips,professional lighting, photon mapping, radiosity, physically-based rendering,extremely detailed eyes and face, beautiful detailed eyes,light on face,cinematic lighting, short jacket,hoodie,school uniform,1girl,full body,full-body shot,see-through,looking at viewer,outdoors,((white hair)), |
拓展设置
你应该注意到我们在代码块中导入了中文本地化的 WebUI 拓展,接下来,我们以stable-diffusion-webui-localization-zh_CN 为例展示 Stable Diffusion WebUI 的灵活拓展能力。
请注意,我在发布本文后修改了代码块的初始化脚本,并引入了更美观的 UI 主题布局。因此,你看到的界面与下文展示的截图略有不同。
下载拓展
进入到 拓展 Extensions 界面,可以看到已经预先安装的中文本地化拓展,如下图所示: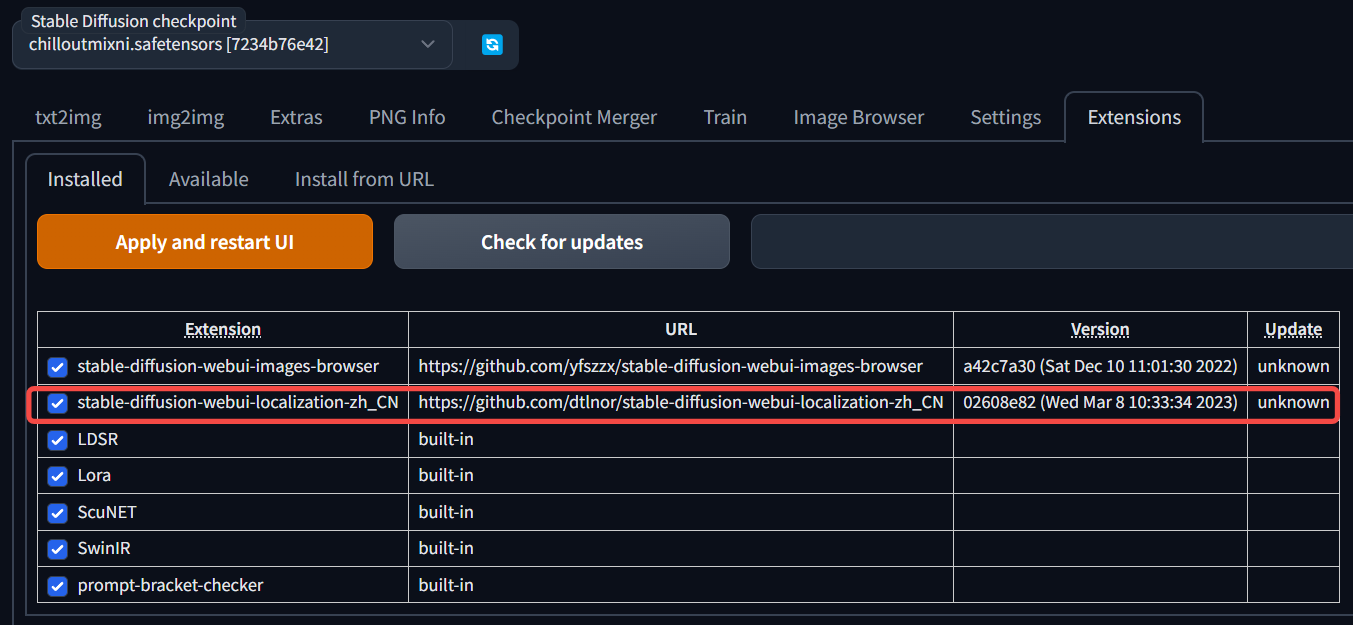
应用拓展
依次进入 设置 Settings → 用户界面 User interface,滑倒最下,找到 Localization,选择 zh_CN。
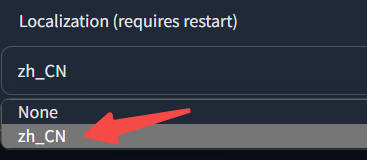
回到上方点击 应用设置 Apply settings,等待后台脚本运行,出现如下 Debug 信息后,点击 重载界面 Reload UI 即可应用拓展。

如果出现 No interface is running right now 的提示,说明 Gradio 前端链接已经刷新,回到你的 Colab 控制台获取新的页面链接。


重启界面
进入 Stable Diffusion WebUI 后,可以看到主要按钮的名称已经本地化。之后,可以按照这个方法更新 UI 和中文本地化拓展。
飞向宇宙,浩瀚无垠
值得注意的是,这个 UI 系统与 Stable Diffusion 社区生态相互连接。通过简单的鼠标操作,您可以轻松地访问 GitHub、CLIP Community 和 Civitai 上的开源内容。此外,在 Panel 面板上还可以方便地整理数据集和进行小型模型训练。
更重要的是,AIGC 的社区生态正在蓬勃发展中。Stable Diffusion、UI、Extensions 以及 GAN 和 Upscale 等应用研究领域都在不断更新迭代。
这只是一个简单的开端,接下来您可以借助开源社区的力量,深入探索 Stable Diffusion 宇宙的广阔世界,并进一步完善它。
LoRA 最佳实践
Things to note if you’ve used my other LORAs: -
Things to note if you've used my other LORAs: -
1. It has more variation, and less consistent in making the same types of faces, it is easier to have more facial expressions due to this.
2. Different LORA weight control would easily change the face variation.
Explanation:
1. This is a LORA trained for sd1.5, the trigger words are 'girl' and 'woman', or you could control the weight with LORA taiwanDollLikeness_v10 prompt.
2. This LORA works extremely well with ChilloutMix and potentially any other photorealistic models, including nsfw models.
3. Works okay when used together with PureErosFace but you must know how to control the weights properly.
https://civitai.com/models/4514/pure-eros-face
5. May also work together with 'ulzzang-6500' but weight control is a must.
https://civitai.com/models/8109/ulzzang-6500-korean-doll-aesthetic
6. Try to use hires fix with around 10-20 hires steps, latent upscaling (bicubic antialiased), denoising strength between 0,4-0.7, its given the best results by far.
7. Higher resolution also helps when creating further subjects, hires fix helps greatly with this too.|
8. Best samplers are DPM++ SDE Karras, Euler a, DPM2 a Karras and DPM++ SDE
Caution:
1. Recommended weights for txt2img - 0.5-0.8
2. Recommended weights for img2img - 0.4-0.8Upscaler 最佳实践
Upscaler 是一款 AI 驱动的图像缩放器。在 Stable Diffusion 中,它将参与到图像渲染的过程中,并能够填充图像像素,从而提高成片分辨率和清晰度。通过搭配合适的咒语,可以生成更加锐利的图像细节。
不同种类的 Upscaler 具备不同方向的强化风格,主要分为以下三类:
- 以摄影照片为主题的写实画风;
- 以动画/动漫为主题的二次元画风;
- 以艺术作品为主题的学派画风。
此外,强化方向相同的 Upscaler 也具有不同的强化粒度。例如,有的渲染速度更快,而有的则更加精细。还有一些可以将主体分割出来进行单独强化,例如实现大光圈下主体锐利的浅景深效果。
模型作者认为,LoRA 最佳的 Upscaler 搭档是 Latent(bicubic antialiased),但你可以尝试其他 Upscaler 对小模型输出的影响。以下是社区总结的截至 2023 年 3 月 10 日的 Upscaler 特性表可供参考:
The DEFINITIVE Comparison to Upscalers : StableDiffusion
请注意,此表格仅列出在官方社区中出现的 Upscaler。您可以根据需要将任何 Upscaler 模型放置到 UI 目录下,并加载使用。
| Upscaler | Photos | Paintings | Anime/Animation |
|---|---|---|---|
| LDSR | Much slower than anything else, but very good for photos | Too much random noise | Better, but still noisy |
| BSRGAN | Good, subtly sharp without going too far | Okay, but maybe a bit too smooth | Good, but R-ESRGAN is better |
| ESRGAN_4x | SUPER sharp, good here, but might be a tad too unrealistic | Too grainy, but might be good for a textured paint look | Terrible, worse than non-AI methods |
| R-ESRGAN-General-4xV3 | Okay, like BSRGAN, but a bit too much blur | Ditto | Much better here, but not as good as R-ESRGAN-Anime |
| R-ESRGAN-General-WDN-4xV3 | Closer to BSRGAN | Very good, texture and definition without being overbearing | Also good, also not as good as R-ESRGAN-Anime |
| R-ESRGAN-AnimeVideo | Tends to “unphoto” a subject | Ditto | 2nd best for anime, but Anime6B is better |
| R-ESRGAN-4x+ | Basically BSRGAN | Slightly more texture than BSRGAN | Basically BSRGAN |
| R-ESRGAN-4x+-Anime6B | Straight-up anime dog | Also anime | The best for anime |
| ScuNET-GAN | Too blurry | Too blurry | Average |
| ScuNET-PSNR | Too blurry | Too blurry | Hot garbage |
| SwinIR_4x | Yuck, I see tile lines! | Good, but not as textured as General-WDN | Hot garbage |
TL;DR
| Picture type | Recommendations |
|---|---|
| Photos | LDSR (but it’s slow), or ESRGAN_4x if you want to super-sharp detail and/or speed, or BSRGAN for subtly |
| Paintings | ESRGAN_4x for high paint texture and detail, General-WDN for a better overall look |
| Anime | Anime6B, also good for turning something into anime |
Sampler 最佳实践
社区索引表
| 索引 | 备注 |
|---|---|
| Civitai | CivitAI 的主要功能包括模型分享和社区交流。用户可以在其他用户分享的模型下方回复自己使用该模型生成的样本、参数以及随机种子,这可以帮助我们快速调试其他人的模型并借鉴他们的输出结果,避免自己在生成过程中的不太理想的表现。 |
| ChilloutMix | 这个模型擅长于生成亚洲女性特征的图片 |
| LoRAs | LoRA(Low-Rank Adaptation of Large Language Models)简单来说,就是通过少量的图像来对 AI 进行额外的学习和训练,从而在一定程度上控制结果。当前比较流行的分支有LoRA-KoreanDoll、LoRA-TaiwanDoll、LoRA-JapaneseDoll,它们分别针对韩国女性、台湾女性和日本女性的风格进行输出。 |
| PromptHero | 如果您不确定如何描述您的内容主体,可以通过搜索您要描述的对象(如:girl, cat, hero),查看网友提供的展示案例,选择您感兴趣的图片并查看其对应的描述。这是对新手很有帮助的辅助工具。 |
| awesome-stable-diffusion | 任何热门技术都会有一个 Awesome 列表。如果你是新手,这个列表将对你很有帮助,它可以让你拓展知识领域,了解Stable Diffusion 社区中出现频率最高的项目/术语/关键词以及相关描述。 |
| stablediffusion-v2 | High-Resolution Image Synthesis with Latent Diffusion Models |
| stable-diffusion-webui | A browser interface based on Gradio library for Stable Diffusion |
| ControlNet | ControlNet is a neural network structure to control diffusion models by adding extra conditions. |